LUCID: Attention with Preconditioned Representations
torch.linalg.solve_triangular (cuBLAS TRSM).TL;DR
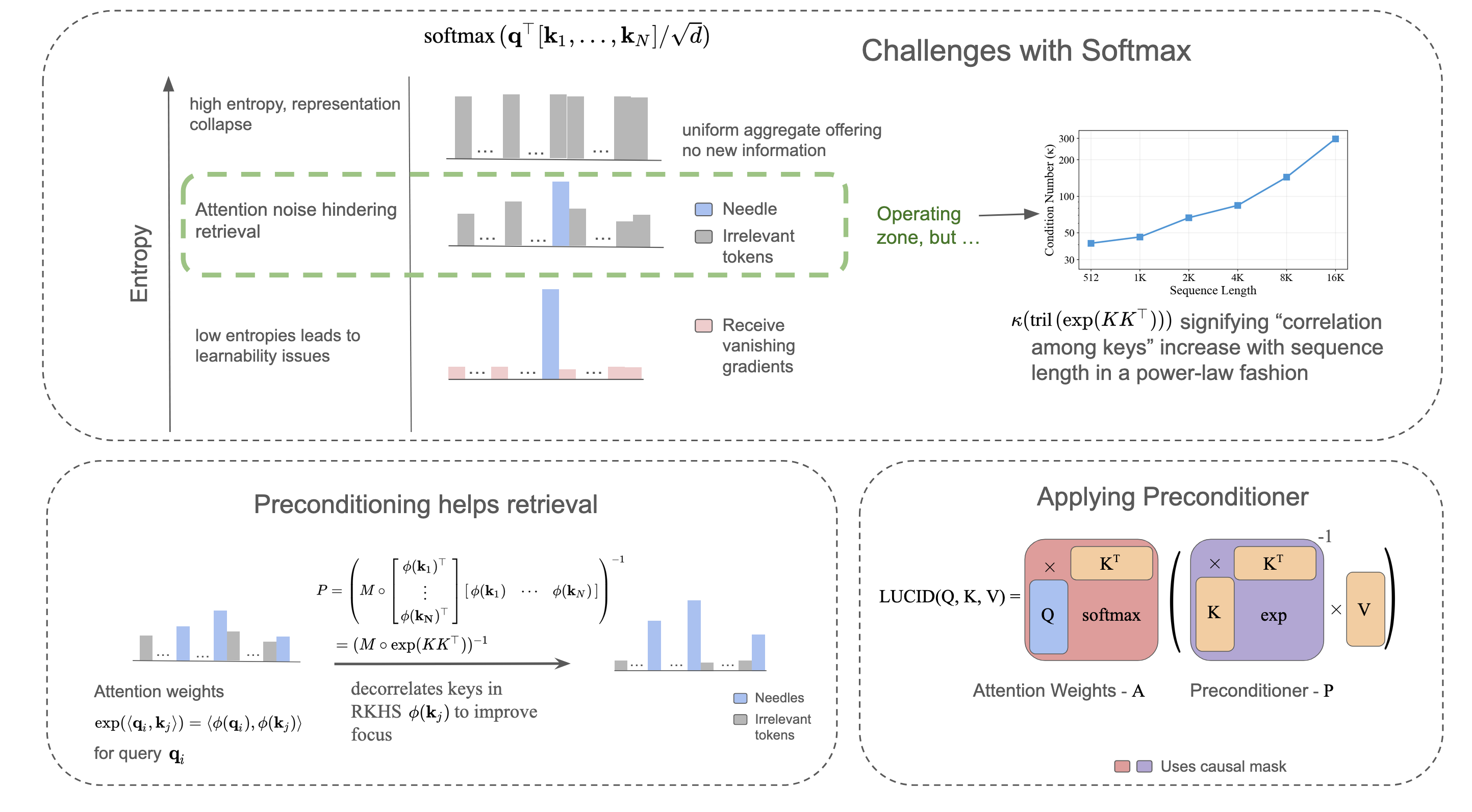
The condition number of the key correlation matrix grows with sequence length, making softmax attention increasingly noisy at long contexts. Tuning the attention entropy can't fix this — lower entropy causes vanishing gradients, higher entropy causes representation collapse. LUCID preconditions the key correlations to decorrelate keys without changing the entropy: a drop-in replacement with up to 14% improvement on RULER multi-needle retrieval, 18% improvement on BABILong long-context reasoning, and ~1.3% inference overhead.
The Problem: Attention Noise at Long Contexts
Softmax attention computes a probability distribution over all keys for each query. As the sequence length $n$ grows, this distribution must cover more and more tokens. Even if most tokens are irrelevant, softmax still assigns them non-zero probability — it cannot output exact zeros.
This is the attention dilution problem: the probability mass that should concentrate on a handful of relevant tokens gets spread thin across thousands of irrelevant ones. For tasks like needle-in-a-haystack retrieval at 128K context, this dilution directly degrades performance.
The Entropy Paradox
Standard attention computes:
$$\text{Attention}(Q, K, V) = \text{softmax}\!\left(\frac{QK^\top}{\sqrt{d}}\right) V$$The entropy of the attention distribution $a = \text{softmax}(q^\top [k_1, \ldots, k_N] / \sqrt{d})$ is determined by how the learned $Q$ and $K$ projections shape the logits. This entropy must land in a narrow operating zone:
Low entropy (sharp, peaked distributions) enables precise retrieval — but creates vanishing gradients. As the distribution approaches one-hot, the softmax Jacobian approaches zero everywhere. The model can no longer learn [8, 9].
High entropy (flat, uniform distributions) keeps gradients healthy — but causes representation collapse [9]. All queries retrieve nearly the same weighted average, destroying the model's ability to distinguish between tokens.
As context grows, attention tends to drift into the high-entropy zone — a phenomenon observed in prior work like Differential Transformer [6]. LUCID's key insight is that we shouldn't be fighting entropy at all; the root problem lies elsewhere.
Root Cause: Correlated Keys
To understand why attention dilutes, consider what softmax actually computes. The exponential kernel $\exp(\langle \cdot, \cdot \rangle)$ induces a Reproducing Kernel Hilbert Space (RKHS) with feature map $\phi$, where inner products in this space equal exponentiated inner products in the original space. The attention weights are determined by the key correlation matrix in this RKHS:
$$G_{ij} = \exp\!\left(\frac{k_i^\top k_j}{\sqrt{d}}\right) = \langle \phi(k_i), \phi(k_j) \rangle$$A critical property: since $G_{ij}$ is an exponentiated inner product, $G_{ij} > 0$ for all $i, j$. Every pair of keys is always positively correlated in the RKHS. There are no negative or zero entries — the feature-space keys $\phi(k)$ cannot be orthogonal.
The condition number $\kappa(G)$ of this matrix measures how correlated the keys are. When $\kappa$ is large, many keys point in similar directions in the RKHS, making it hard for softmax to distinguish between them. As sequence length increases, the condition number grows because more keys packed into a finite-dimensional space inevitably become more correlated. This is the fundamental cause of attention dilution.
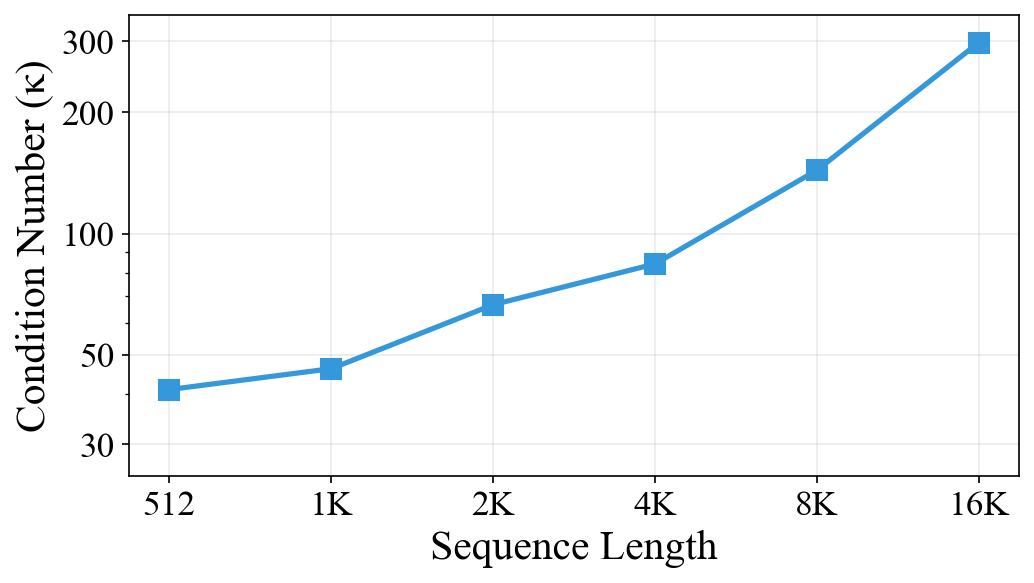
The condition number grows with sequence length due to accumulating key correlations. This empirically validates that LUCID's advantage increases for longer sequences where key correlations are worst.
The LUCID Method
Softmax Attention as Gradient Descent in RKHS
Following Katharopoulos et al. [2] ("Transformers are RNNs"), the exponential inner product in softmax attention can be expressed using a kernel function:
$$\exp\!\left(\langle q_i, k_j \rangle\right) = \langle \phi(q_i), \phi(k_j) \rangle$$where $\phi: \mathbb{R}^d \to \mathcal{H}$ is a feature map to a Reproducing Kernel Hilbert Space (RKHS). Using this view, we can interpret unnormalized softmax attention as gradient descent on a linear objective. At each step $t$, we maintain a state matrix $S: \mathcal{H} \to \mathbb{R}^d$ that stores key-value associations:
$$f_t(S) = -v_t^\top S\,\phi(k_t)$$The gradient $\nabla_S f_t(S) = -v_t\,\phi(k_t)^\top$ yields the additive update:
$$S_t = S_{t-1} + v_t\,\phi(k_t)^\top$$This is precisely the update underlying standard linear attention. But the linear objective has fundamental limitations: it is unbounded from below, the updates are state-independent (occurring regardless of whether the association is already stored), and each update accumulates interference without removing old information.
Quadratic Objective → Delta Rule in RKHS
Following Yang et al. [3] (DeltaNet, arXiv:2406.06484), a more principled approach uses a quadratic objective that directly measures retrieval error:
$$f_t(S) = \frac{1}{2}\|S\,\phi(k_t) - v_t\|^2$$This objective is bounded below by 0, with a clear minimum at $S\,\phi(k_t) = v_t$. The gradient descent update with step size $\beta_t = 1$ yields the delta rule in RKHS:
$$S_t = S_{t-1}(I - \phi(k_t)\,\phi(k_t)^\top) + v_t\,\phi(k_t)^\top$$This is an erase-then-write mechanism:
$$S_t = S_{t-1} - \underbrace{(S_{t-1}\phi(k_t))\,\phi(k_t)^\top}_{\text{erase old association}} + \underbrace{v_t\,\phi(k_t)^\top}_{\text{write new association}}$$A key advantage is self-regulation: when the current prediction is already correct ($S_{t-1}\phi(k_t) = v_t$), the gradient is zero and no update occurs. This property is absent in the linear objective, which blindly updates regardless.
Why RKHS, Not Key Space? (LUCID vs DeltaNet)
The delta rule update above is precisely DeltaNet [3, 4], but generalized from finite-dimensional key space to the infinite-dimensional RKHS induced by the exponential kernel. The key differences:
- DeltaNet: Uses the identity map $\phi(x) = x$, operating in the $d$-dimensional token space. The preconditioner $(I + \text{stril}(KK^\top))^{-1}$ decorrelates keys in this finite-dimensional space. When keys are orthogonal ($k_i^\top k_j = 0$), DeltaNet's correction vanishes.
- LUCID: Uses the exponential kernel feature map $\phi: \mathbb{R}^d \to \mathcal{H}$, operating in an infinite-dimensional RKHS. The preconditioner $(M \circ \exp(KK^\top))^{-1}$ decorrelates keys in this richer space. Since $\exp(k_i^\top k_j) > 0$ always, LUCID's correction never vanishes.
This distinction matters at long contexts. Keys live in a finite head dimension (e.g., $d = 128$), so at sequence lengths like 128K, the $d$-dimensional key space is far too small to accommodate 128K nearly-orthogonal vectors — keys inevitably interfere, and DeltaNet's correction in this crowded space is limited. The RKHS induced by the exponential kernel, however, is infinite-dimensional. The feature-space representations $\phi(k)$ have the potential to be far less correlated in this richer space, and LUCID's preconditioner exploits this by decorrelating them, enabling precise retrieval even when the original keys are highly entangled.
The Key Equation
The recurrent delta rule can be computed in parallel. Collecting outputs for all tokens and introducing standard $1/\sqrt{d}$ logit scaling plus RMS normalization for the keys inside the preconditioner ($k_{i,\text{RN}} \leftarrow \sqrt{d} \cdot k_i / \|k_i\|_2$), we arrive at the LUCID attention formula:
$$\text{LUCID}(Q,K,V) = \text{softmax}\!\left(\frac{QK^\top}{\sqrt{d}} + \hat{M}\right) \cdot \left(M \circ \exp\!\left(\frac{K_{\text{RN}}K_{\text{RN}}^\top}{\sqrt{d}} - \sqrt{d}\right)\right)^{\!-1} V$$where $K_{\text{RN}}$ denotes the RMS-normalized keys, $M$ is the binary causal mask ($M_{ij} = 1$ if $i \ge j$), and $\hat{M}$ is its additive form ($\hat{M}_{ij} = 0$ if $i \ge j$, $-\infty$ otherwise). The middle term is the preconditioner — it inverts the key correlation structure, decorrelating the keys before the attention output is computed. The RMS normalization ensures unit diagonal entries and controlled off-diagonal magnitudes, yielding better condition numbers.
Practical Implementation
The intention is to precondition the keys and thereby the attention probabilities formed by query-key correlations. However, we found that multiplying the preconditioner with the values $V$ instead is mathematically equivalent — since matrix multiplication is associative, $(\text{softmax}(\cdots) \cdot P^{-1}) V = \text{softmax}(\cdots) \cdot (P^{-1} V)$. This reformulation has two practical advantages:
- One preconditioner per KV head: The preconditioner $P$ depends only on keys, so it is shared across all query heads in the same KV group. Instead of preconditioning every query head's attention weights, we precondition the values once per KV head.
- Linear solve instead of matrix inverse: Rather than explicitly computing $P^{-1}$ and multiplying, we solve the linear system $PY = V$. Since $P$ is lower triangular (thanks to the causal mask $M$), this is just forward substitution — $O(N^2 d)$ complexity, the same as standard attention.
In practice, we use torch.linalg.solve_triangular, which dispatches to the cuBLAS TRSM (Triangular Solve) kernel — a highly optimized divide-and-conquer routine on GPU. Modern LLMs use Grouped-Query Attention (GQA) with far fewer KV heads than query heads (e.g., 4 KV heads for 32 query heads in our 1B model), so the triangular solve is only performed 4 times, not 32, keeping overhead minimal:
- Training overhead: ~0–5.5% depending on architecture (0% for Gemma 3-1B, 3.5% for Gemma 3-4B, 5.5% for Qwen 2.5-1.5B)
- Inference overhead: ~1.3% (77ms vs 76ms at 32K context with 100 new tokens)
A compute ablation confirms these gains are architectural, not from extra compute: training the baseline 10% longer does not match LUCID's multi-needle retrieval performance.
Learnability
The Softmax Gradient Problem
A critical requirement for attention mechanisms is the ability to represent sharp distributions — when a query $q_i$ matches a specific key $k_j$, attention should concentrate on the corresponding value $v_j$. In standard softmax, the way to achieve this is to lower the temperature, pushing the output toward a one-hot vector:
$$\text{softmax}(z / \tau) \xrightarrow{\tau \to 0} e_{\arg\max z}$$But this kills learning. The softmax Jacobian is:
$$J = \frac{\partial a}{\partial \tilde{a}} = \text{diag}(a) - aa^\top$$When $a = e_i$ (one-hot), we get $J = \text{diag}(e_i) - e_i e_i^\top = 0$. Zero Jacobian means zero gradients — learning stops completely. This creates a fundamental dilemma: standard attention can either retrieve precisely (low temperature, no gradients) or learn effectively (higher temperature, blurred retrieval).
LUCID Decouples Retrieval from Entropy
LUCID resolves this tension by achieving sharp retrieval through the preconditioner $(M \circ \exp(KK^\top))^{-1}$ rather than by lowering the softmax temperature. The softmax operates at standard temperature with a well-conditioned gradient, while the preconditioner sharpens the final output through deconvolution. This fundamental decoupling enables LUCID to achieve both precise retrieval and effective learning simultaneously.
Theorem (Gradient Preservation). Let $o$ be the LUCID attention output (before multiplying by $V$). Assume $K \neq 0$ and at least one column of $\text{diag}(a) - aa^\top$ is not in the null-space of $K^\top$, where $a = \text{softmax}(qK^\top / \sqrt{d})$. Then $\partial o / \partial q \neq 0$.
The proof follows from the Jacobian decomposition:
$$\frac{\partial o}{\partial q} = \frac{K^\top}{\sqrt{d}} \left(\text{diag}(a) - aa^\top\right) \left(M \circ \exp\!\left(\frac{K_{\text{RN}}K_{\text{RN}}^\top}{\sqrt{d}} - \sqrt{d}\right)\right)^{\!-1}$$Since the preconditioner is a lower-triangular matrix with positive diagonal entries, it is invertible with trivial null-space. The gradient can only vanish if the softmax becomes one-hot — but LUCID doesn't need low temperature, so this doesn't happen.
Synthetic Experiment: Sequential Task Learning
To empirically validate this, we designed a two-phase experiment on a single-layer transformer (dim 256, 1 head, sequences of length 10):
- Phase 1 (Self-Retrieval): Learn to copy the input ($y_i = x_i$). Requires sharp, identity-like attention.
- Phase 2 (Cumulative Averaging): Without resetting weights, switch to computing $y_i = \frac{1}{i}\sum_{j=1}^{i} x_j$. Requires adapting from sparse to dense distributions.
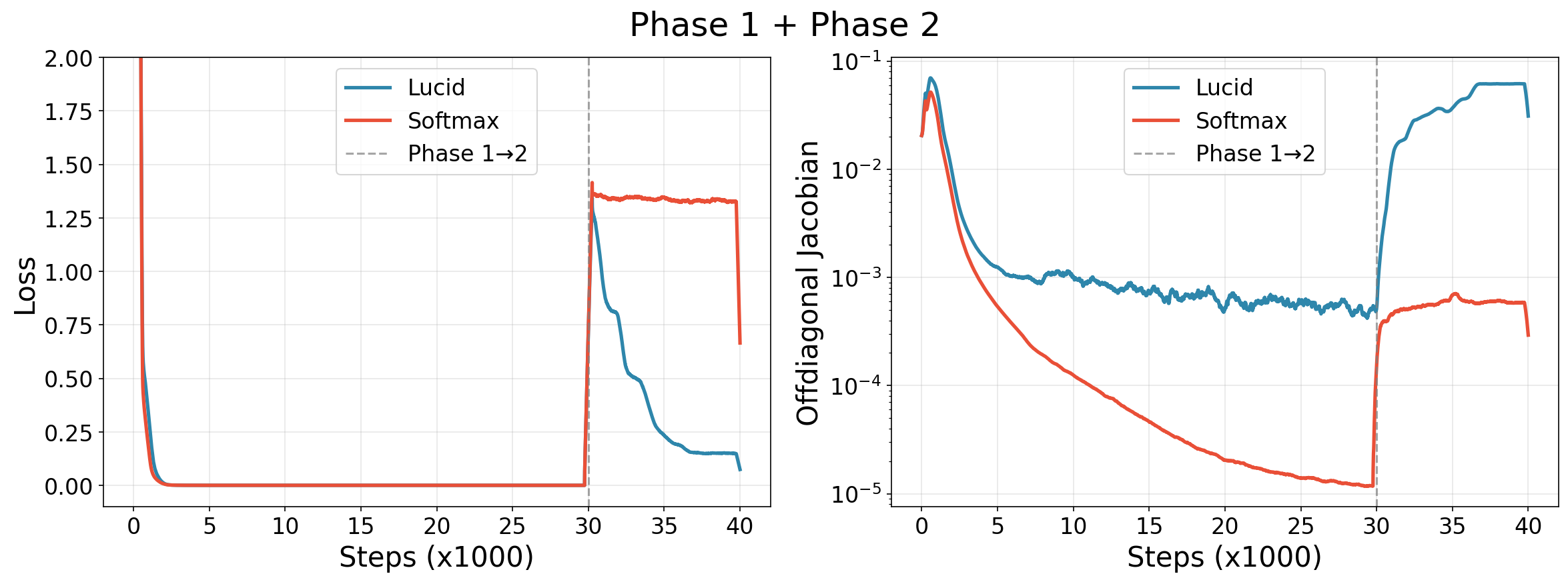
During Phase 1, both methods achieve near-zero loss. But standard softmax achieves sharpness by progressively reducing its Jacobian $(\text{diag}(a) - aa^\top)$ by approximately three orders of magnitude — effectively lowering its implicit temperature. When Phase 2 arrives, this near-zero Jacobian blocks gradient flow and the model cannot adapt. LUCID, having achieved sharpness through its preconditioner while maintaining higher Jacobian magnitudes, rapidly adapts to the new task.
Results
LUCID is evaluated on ~1B parameter language models (22 layers, model dim 2048, 32 query heads, 4 KV heads) with context windows up to 128K tokens. It is a drop-in replacement for standard attention — no architectural changes, no additional parameters.
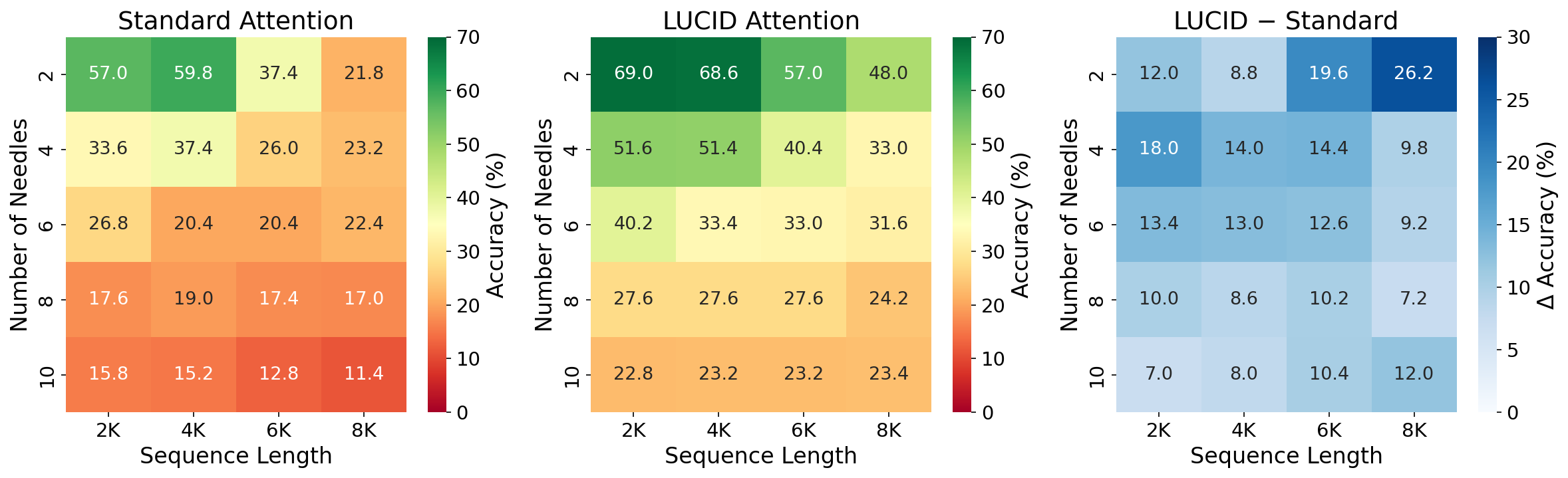
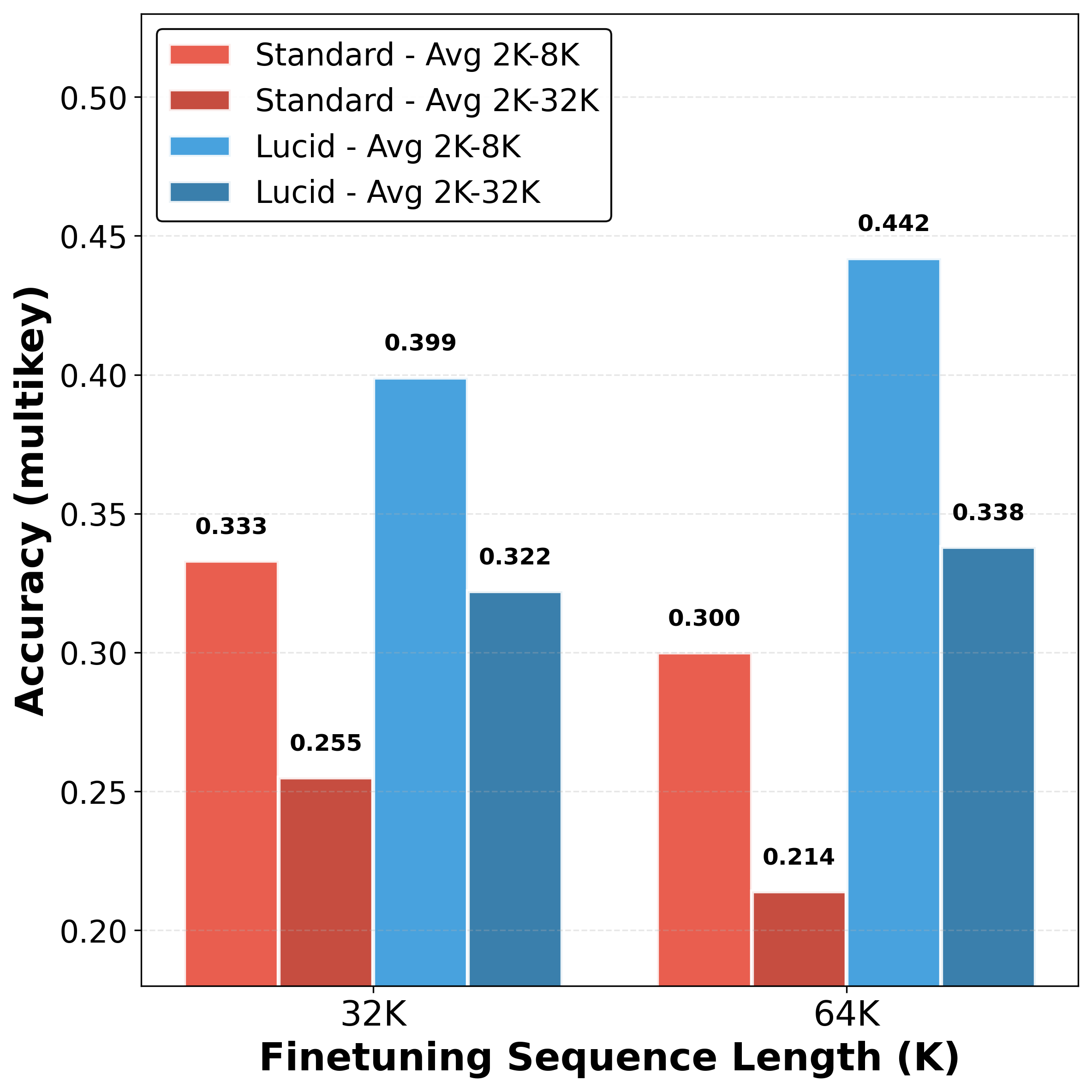
Multi-Needle Retrieval (RULER)
On the RULER [10] multi-needle retrieval benchmark:
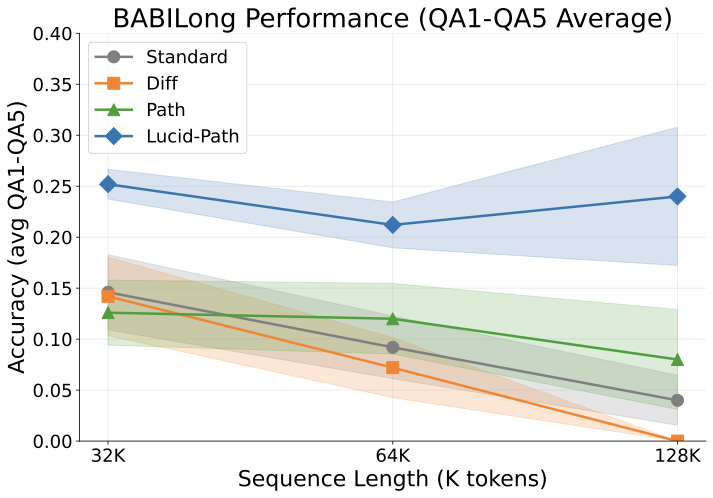
BABILong
BABILong [13] tests multi-hop fact retrieval and reasoning across long contexts (32K–128K tokens). We introduce LUCID-PaTH, which combines LUCID's key decorrelation with PaTH positional encoding [7] for length extrapolation.
LongBench & SCROLLS
On the LongBench [11] and SCROLLS [16] real-world long-document benchmarks (multi-document QA, single-document QA, summarization), LUCID and LUCID-PaTH achieve the best performance on 4 of 6 tasks. Linear attention variants (DeltaNet, GLA, GSA) underperform substantially — e.g., DeltaNet achieves only 0.036 F1 on 2WikiMQA compared to 0.274 for LUCID.
Attention Hitrate
To directly measure whether LUCID reduces attention noise, we measure the attention hitrate — the fraction of attention weight placed on semantically relevant ("needle") tokens during retrieval:
- Standard Attention: 0.1817
- LUCID Attention: 0.2845 — a 56.6% improvement
This directly confirms that LUCID's preconditioner concentrates probability mass on the right tokens.
Want to Work Further on LUCID?
(a) Distillation for Foundation Models
Our experiments train from scratch at ~1B scale. A natural next step is to use distillation to create LUCID+PaTH variants of existing foundation models (Qwen, Gemma, Llama, etc.) for ~1M context, where $\kappa$ blows up and LUCID's correction becomes most essential. This would bring LUCID's benefits to production-scale models without full pretraining.
(b) Efficient Kernels
The current implementation uses the cuBLAS TRSM kernel for the triangular solve. Two promising directions for further optimization:
- Interleaved solver + FlashAttention: Fuse the triangular solve with the FlashAttention softmax pass into a single kernel to reduce memory traffic.
- Neumann series approximation: Write the inverse as $(I - A)^{-1} = I + A + A^2 + \ldots$ and compute the truncated series using FlashAttention-like tiled algorithms. This could enable fully IO-aware implementations.
(c) Bidirectional Models
LUCID's efficient implementation relies on the preconditioner being lower triangular (from the causal mask). For bidirectional settings — such as diffusion models or encoders — the preconditioner loses this structure. One approach: use Newton-Schulz iteration (as in the Muon optimizer) to approximate the inverse, which primarily involves bf16 matrix multiplications and could be made efficient on modern hardware.
References
- Vaswani et al. "Attention Is All You Need." NeurIPS 2017. arXiv:1706.03762
- Katharopoulos et al. "Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention." ICML 2020. arXiv:2006.16236
- Yang et al. "Parallelizing Linear Transformers with the Delta Rule over Sequence Length." 2024. arXiv:2406.06484
- Schlag et al. "Linear Transformers Are Secretly Fast Weight Programmers." ICML 2021. arXiv:2102.11174
- Yang et al. "Gated Delta Networks: Improving Mamba2 with Delta Rule." 2024. arXiv:2412.06464
- Ye et al. "Differential Transformer." 2025. arXiv:2410.05258
- Yang et al. "PaTH Attention: Position Encoding via Accumulating Householder Transformations." 2025. arXiv:2505.16381
- Zhai et al. "Stabilizing Transformer Training by Preventing Attention Entropy Collapse." ICML 2023. arXiv:2303.06296
- Masarczyk et al. "Unpacking Softmax: How Temperature Drives Representation Collapse, Compression, and Generalization." 2025. arXiv:2506.01562
- Hsieh et al. "RULER: What's the Real Context Size of Your Long-Context Language Models?" 2024. arXiv:2404.06654
- Bai et al. "LongBench: A Bilingual, Multitask Benchmark for Long Context Understanding." 2023. arXiv:2308.14508
- Brown et al. "Language Models are Few-Shot Learners." NeurIPS 2020.
- Kuratov et al. "BABILong: Testing the Limits of LLMs with Long Context Reasoning-in-a-Haystack." NeurIPS 2024. arXiv:2406.10149
- Dao & Gu. "Transformers are SSMs: Generalized Models and Efficient Algorithms through Structured State Space Duality." 2024. arXiv:2405.21060
- Weston et al. "Towards AI-Complete Question Answering: A Set of Prerequisite Toy Tasks." 2015. arXiv:1502.05698
- Shaham et al. "SCROLLS: Standardized CompaRison Over Long Language Sequences." 2022. arXiv:2201.03533
- Soldaini et al. "Dolma: An Open Corpus of Three Trillion Tokens for Language Model Pretraining Research." 2024.
- Team et al. "Gemma 3 Technical Report." 2025. arXiv:2503.19786
- Team et al. "Qwen2 Technical Report." 2024. arXiv:2407.10671
- Su et al. "RoFormer: Enhanced Transformer with Rotary Position Embedding." Neurocomputing 2024.
- Gao et al. "The Language Model Evaluation Harness." 2024. Zenodo
- Zhang et al. "Gated Slot Attention for Efficient Linear-Time Sequence Modeling." 2024. arXiv:2409.07146